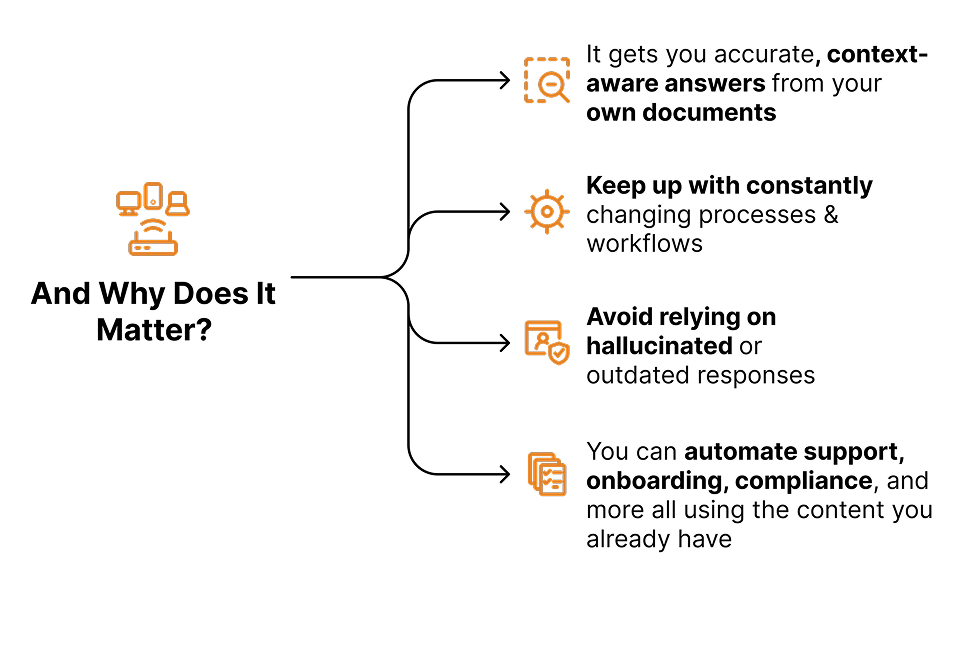
Your team spends hours digging through internal documents just to answer basic operational questions. New employees take weeks…sometimes months, to onboard, not because the training is slow, but because your company’s knowledge is fragmented across wikis, PDFs, Slack threads, and legacy systems. And with processes and data constantly changing as your business changes, no one knows where the latest version lives or what’s still accurate.
You’re not alone. According to a McKinsey report, employees spend nearly 20% of their workweek, almost a full day, searching for internal information or tracking down colleagues who can help. Another study by IDC estimates that a company with 1,000 knowledge workers loses over $2.5 million annually in productivity due to this very problem
What is RAG (Without the Jargon)?
RAG stands for Retrieval-Augmented Generation. It combines two AI powers:
- 1. Understanding language and context (like ChatGPT)
- 2. Retrieving accurate answers from your own content like docs, tickets, policies, emails, and more.
Unlike public AI models that generate output based on just its own training data & general internet knowledge (has a chance of guessing & hallucinating), RAG pulls the right information from your internal system knowledge and grounds its answers in your private, evolving data.

It’s like giving AI secure, contextual, and real-time access to your internal knowledge so that it can give precise, reliable answers grounded in your own
How Does RAG Work?
From Query to Response: A Step-by-Step Process


the Vector Database

retrieved

is sent to the LLM

grounded response

returned to the user

Real-Life RAG Use-cases We handled

E-Commerce & Retail
Problem: Customers get frustrated digging through FAQs or product pages just to understand if item X works with their machine-washable?
RAG Solution: A smart assistant fetches answers directly from product manuals, catalogs, and reviews—no guessing, no blanks, watching.

Healthcare & Pharma
Problem: Clinical trial teams struggle to sift through thousands of research papers and regulatory docs, which slows down drug development timelines.
RAG Solution: RAG enables instant retrieval of relevant trial data, past study results, and compliance guidelines, helping researchers accelerate discoveries.

Banking & Insurance
Problem: Customers struggle to understand whether their policy or coverage actually applies to their situation.
RAG Solution: RAG finds the exact clause in their contract and explains it clearly, in plain English.

Manufacturing & Supply Chain
Problem: On-site engineers lose time scanning manuals whenever machines throw up error codes.
RAG Solution: Ask the code, and RAG retrieves the right troubleshooting step straight from the manual; no delay, no confusion.

Legal Industry
Problem: Junior associates spend days searching through case law for precedents.
RAG Solution: RAG brings up the most relevant cases in minutes, making research dramatically faster.

Energy & Utilities
Problem: Compliance managers drown in paperwork when verifying regulatory requirements.
RAG Solution: RAG finds and summarizes the right EPA or emission standard instantly, saving days of manual work.
Why RAG-Powered AI Outperforms Rule-Based Logic and Fine-Tuned Models?
In the world of LLMs, context is critical. RAG provides real-time context without the fragility of rules or the overhead of fine-tuning. Here’s how it compares at a glance.
| Capability / Criteria | RAG (Retrieval-Augmented Generation) | Rule-Based Systems | Fine-Tuned LLMs |
|---|---|---|---|
| Adaptability to Changing Information | dynamically fetches latest content at query time. | requires manual rule updates whenever data changes. | requires retraining to reflect new information. |
| Contextual Understanding | uses up-to-date, task-specific context from internal sources. | operates on static logic with no contextual awareness. | context is baked in at training time, not real-time. |
| Data Requirement | relies on a retrievable knowledge base | logic hardcoded | requires curated, labeled datasets |
| Setup Cost | building a retrieval system | rules are manually coded | Needs GPU, large & clean datasets and back end setup to train & deploy |
| Deployment Speed | can be implemented quickly with minimal prep. | rule creation takes time and testing. | training and model tuning are time-intensive. |
| Maintenance Effort | content updates automatically affect outputs. | ongoing manual updates to logic and conditions. | re-training and versioning required for updates. |
| Scalability Across Use Cases | one model can serve multiple domains via different content. | rules must be defined separately for each use case. | may require multiple models for different domains. |
| Response Flexibility | handles a wide range of query types with relevant results. | only answers what’s explicitly programmed. | handles variants, but only within trained scope. |
| Cost to Update | no retraining; just update the source content. | each change needs manual rule edits. | significant cost for retraining cycles. |
| Security with Proprietary Data | can work with private infra, no external calls needed. | if built and hosted internally. | may expose data during training unless built in-house. |
But How Do You Know If RAG Makes Sense For Your Business?
If you’re thinking, “There’s a new AI trend every other week,do I really need this one?” Fair question…But RAG isn’t just another model – it is one of the first AI architectures that effectively bridges the gap between large language models and enterprise knowledge, solving a problem that previous systems could only partially address.
To help you figure, if RAG is truly needed by your organization, here’s a simple diagnostic:

Need for AI that retrieves internal truth, not just public information.

Your knowledge changes constantly due to fast-evolving processes
You’re sitting on a mountain of messy internal content

Need to keep company confidential data out of public AI models.

Static systems fail to adapt to nuanced and unexpected questions.

In need of Context-Aware Automation thats accurate & real-time

Scaling Issues : Human training can’t keep up
Knowledge walks out the door with employees
Where Can You Implement RAG For Maximum Benefit?
Most teams today struggle with fragmented and fast-evolving knowledge. Whether it’s a product spec tucked away in a document page, a pricing detail last updated in a PDF, or a policy that’s changed three times in the last year.
This is where retrieval-augmented generation (RAG) becomes more than just a technical upgrade it becomes a practical necessity.
For Product Teams: Avoiding déjà vu decisions
Take product and service teams. Decisions around feature prioritization, customer needs, or even past trade-offs are often buried in PRDs or Slack threads.
A new team member joins and asks, “Why didn’t we go with X integration?” In a non-RAG world, they’d either ask around or never get an answer. With RAG, your model can surface that exact decision rationale from archived sprint notes or past discussions, instantly and accurately.


For Sales: No more “Let me get back to you”
Customer-facing teams face a different challenge. A sales rep on a call is asked whether your product supports a particular standard or how the pricing model flexes for enterprise clients.
Traditionally, they’d either guess or say, “Let me get back to you.” RAG flips that script. It can reference the most recent pricing sheets, integration guides, or roadmap blurbs, even if they’re updated weekly and respond contextually. No hallucinations, no outdated info, just what’s true right now.
For Support: Response that fits context, not just keywords
Support teams benefit just as much. While bots have existed for years, most fail the moment a query gets slightly nuanced. Customers don’t just ask, “How do I reset my password?” – They ask about exceptions, refund conditions, or edge cases tied to specific plans or timelines.
RAG allows the AI assistant to tap into your internal SOPs, help center docs, or even CRM notes, ensuring every response is grounded in your actual policy. That’s a leap from scripted bots to reliable support automation.


For HR: Answers that know who’s asking
HR teams deal with nuanced, policy-based questions that vary by role or location. RAG lets your assistant retrieve the exact clause from the latest handbook, personalized, accurate, and real-time.
With RAG, you don’t need to hardcode those rules into a chatbot. The assistant can extract the relevant clause from your actual HR handbook or policy doc, dynamically adjusting its answer based on what’s asked. And if the document changes? So does the answer.
Myths to Bust
To unlock RAG’s real potential, it helps to clear up a few common misconceptions that often hold teams back.
Not if it’s done right. Retrieval-augmented generation doesn’t require sending your documents to public LLMs. When built on private infrastructure with secure access layers and role-based permissions, RAG becomes a closed-loop system. Your data stays where it should: inside your environment.


That’s fine, most companies don’t. RAG doesn’t demand polished datasets or perfectly tagged entries. Even cluttered PDFs, legacy SOPs, messy Notion pages, or versioned Word docs can be indexed and parsed with the right preprocessing layer. Structured or not, if your team refers to it, it can become part of your knowledge assistant.
Quite the opposite. RAG thrives wherever teams rely on internal knowledge to make decisions. That includes manufacturing, healthcare, logistics, banking, insurance, and even government orgs and more. If you have complex documentation, changing workflows, or siloed knowledge, RAG can help.

Where RAG Stops and What Takes It Further
At its core, RAG is a powerful enabler. It pulls the right information from your internal knowledge base and feeds it to an LLM, so answers are grounded in your actual content. But on its own, RAG has limits.
RAG retrieves facts, but it doesn’t remember conversations or trigger next steps. That’s where orchestration frameworks like LangChain and LangGraph come in.


LangChain makes RAG smarter…
Instead of just answering questions, it acts like a conductor, guiding each step:
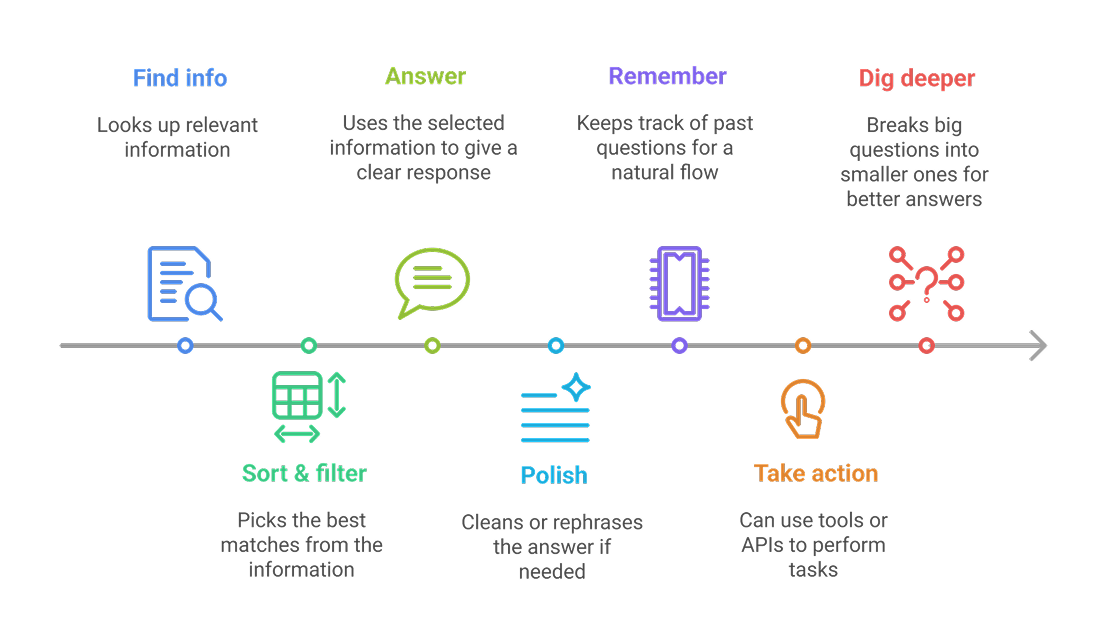

LangGraph adds structure and guardrails.
It’s like a blueprint that keeps the AI on track. LangGraph turns RAG from loose steps into a well-organized, reliable system.


Some of our Past RAG Projects

AI Shopping Companion using by RAG
We built an AI-powered shopping companion using RAG to deliver intent-aware results. It started with retrieval over product catalogs, then evolved to handle multi-constraint queries, detailed specs, ratings, and reviews. With conversational refinements and intent-based ranking, it adapts to budget or premium needs. For retailers, a natural language admin interface enables boosting, compliance, and geo-filters—scaling from MVP to a full-featured RAG solution.
 View Details
View Details  Video Demo
Video Demo 
Multi-Agent RAG Content Generator
We built a reference content generator powered by RAG and LangGraph. It started with retrieving style elements from user docs and extracting topics from links like YouTube or blogs. Over time, we added parallel retrieval of style, topic, and personal documents, enabling draft generation that reflects both expertise and voice. Users refine outputs interactively, and the system can auto-publish to platforms, scaling into a full-featured RAG-driven content creation tool.


Conclusion
If any of this sounded familiar, the scattered knowledge, repeated questions, or clunky search across docs, RAG can quietly take that pain away.
If you’re curious about what this could look like in your org or just want to sanity check whether it’s worth exploring, we’re happy to chat. No jargon. No hard sell. Just clarify on what’s possible (and what’s not).